Indicador 21.1: Indicador sobre información de biodiversidad para el monitoreo del marco mundial de biodiversidad
Última actualización de este notebook: 03-04-2026 20:31
Este indicador evalúa la infraestructura de datos del país. Su objetivo es reportar la capacidad técnica de Chile para monitorear las metas del Marco Kunming-Montreal.
El cálculo se aplica sobre los Indicadores de Cabecera (Headline Indicators) del Marco Global adoptados por el país. No se deben considerar indicadores nacionales complementarios que no tengan equivalencia en la lista oficial de cabecera de la CBD.
Metodología de Cálculo¶
Corresponde a la métrica que resume la disponibilidad de datos.
1. Fórmula de Cálculo¶
2. Criterios de Inclusión (Checklist) Para que un indicador sume al numerador, debe cumplir al menos el nivel “Básico”:¶
Nivel Básico (Cuenta): El indicador fue calculado para el reporte nacional actual, incluso si los datos requirieron gestión interna o procesamiento manual único.
Nivel Óptimo (Ideal): El indicador se alimenta de un flujo de datos automatizado, público y alojado en sistemas oficiales (SINIA/SIMBIO).
3. MÉTRICAS DE CALIDAD Y COBERTURA (DESAGREGACIÓN)¶
El reporte de este indicador no basta con el porcentaje; se deben reportar métricas sobre la representatividad de los datos primarios subyacentes.
Índice de Información de Especies (SII) y Efectividad (SSEI)¶
Mide qué tan bien cubren los registros de biodiversidad (puntos de ocurrencia) el rango geográfico esperado de las especies en el país.
Fuente Oficial: Descargar valores para Chile desde la plataforma Map of Life (MOL).
Reporte: Ingresar el valor (0 a 100) del Species Information Index y Species Sampling Effectiveness Index.
Opción de cálculo según Metodología de Oliver et al. (2021) journal.pbio.3001336.pdf con registros GBIF . En R (paquete spocc o herramientas de WhereNext?) para cruzar puntos vs. grilla de 5x5 km.
Análisis de Vacíos de Muestreo (Survey Gap Analysis)¶
Evalúa qué porciones del espacio geográfico o ambiental de Chile están sub-muestreadas.
Objetivo: Identificar sesgos espaciales y taxonómicos.
Metodología Simplificada:
Utilizar la base de datos de GBIF Chile.
Superponer los puntos de ocurrencia sobre las Ecorregiones o Pisos Vegetacionales oficiales.
Identificar cuántas ecorregiones tienen “Datos Insuficientes” (ej. menos de 10 registros por cada 100 km²).
Metodología Avanzada (Nivel Recomendado COP16):
Utilizar herramientas de modelación como “Where Next?” o modelos GDM (Generalized Dissimilarity Modelling).
Estas herramientas calculan la distancia entre un punto muestreado y un punto no muestreado en términos ambientales.
Dato a Reportar: “Porcentaje del territorio nacional (o de ecorregiones) identificado como vacío de información prioritaria”.
CRS = "EPSG:32719"Capa 1: Observación y recolección¶
Fuentes de Datos Utilizadas¶
Ocurrencias GBIF¶
Las ocurrencias fueron obtenidas desde la consulta de GBIF disponible en: GBIF.org User (2026). Se realiza la ingesta de estos datos a la basen de datos intermedia utilizando el script de Python process_gbif.py.
gbif = gpd.read_postgis("""
SELECT *
FROM processed.gbif_occurrences;
""", engine, geom_col="geometry", crs=CRS)
gbifWARNING: database "7nr" has a collation version mismatch
DETAIL: The database was created using collation version 2.41, but the operating system provides version 2.31.
HINT: Rebuild all objects in this database that use the default collation and run ALTER DATABASE "7nr" REFRESH COLLATION VERSION, or build PostgreSQL with the right library version.
Capas Ecorregiones y Pisos Vegetacionales¶
Sen extraen desde la plataforma desde el Geoportal Simbio. Los shapefile fueron procesados utilizando el script de Python process_layers.py.
Ecorregiones¶
ecorregiones = gpd.read_postgis("""
SELECT *
FROM processed.ecorregiones;
""", engine, geom_col="geometry", crs=CRS)
ecorregionesPisos Terrestres¶
pisos = gpd.read_postgis("""
SELECT *
FROM processed.pisos_vegetacionales;
""", engine, geom_col="geometry", crs=CRS)
pisosCPU times: user 42.3 s, sys: 13.7 s, total: 56 s
Wall time: 1min 3s
Pisos Terrestres¶
%%time
joined = gpd.sjoin(gbif, pisos, how='left', predicate='within')
point_counts = joined.groupby('index_right').size().reset_index(name='point_count')
result_terrestre = pisos.copy()
result_terrestre = result_terrestre.merge(point_counts, left_index=True, right_on='index_right', how='left')
result_terrestre['point_count'] = result_terrestre['point_count'].fillna(0).astype(int)
result_terrestre['densidad'] = result_terrestre["point_count"] * 100 / result_terrestre["Sup_Total"]
result_terrestre['more_than_10'] = result_terrestre['densidad'] >= 10
result_terrestre['densidad_log'] = np.log1p(result_terrestre['densidad'])
result_terrestreCPU times: user 39 s, sys: 15.2 s, total: 54.2 s
Wall time: 1min 1s
Capa 3: Repporte Digital¶
Debido a los altos valores de algunas zonas, se presenta el logaritmo de la cantidad de observaciones por cada
Ecorregiones¶
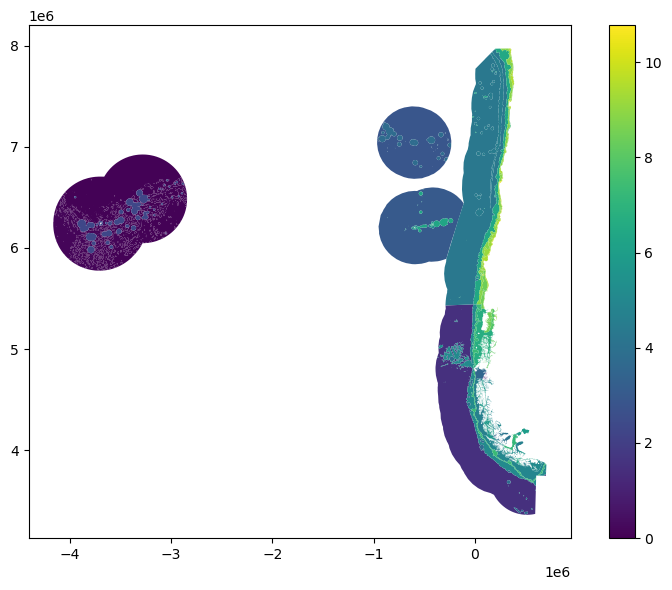
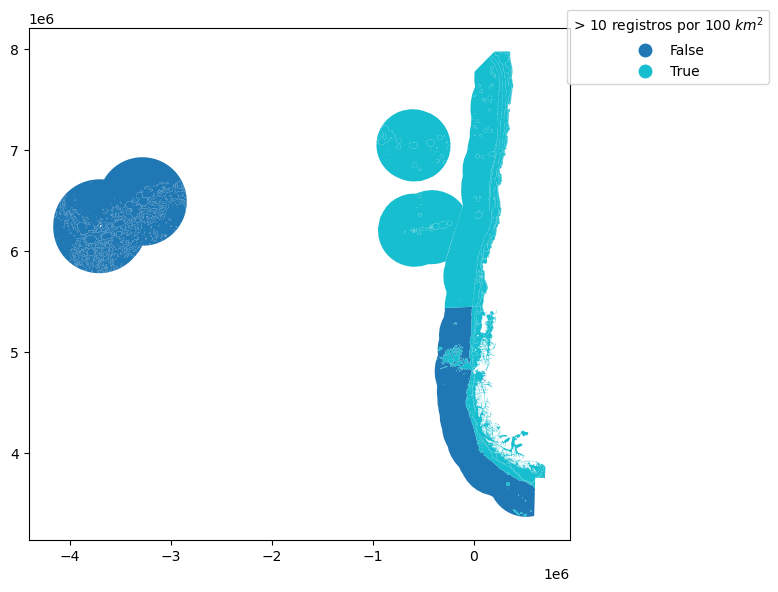
Porcentaje de ecorregiones con datos suficientes (> 10 por 100 km²): 87.78 %
Porcentaje de área con datos suficientes (> 10 por 100 km²): 60.90 %
Pisos Vegetacionales¶
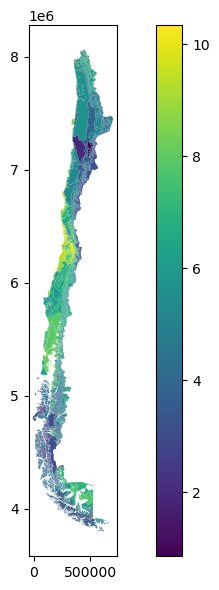
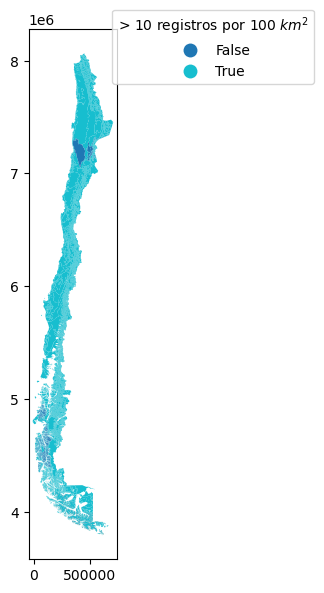
Porcentaje de ecorregiones con datos suficientes (> 10 por 100 km²): 96.83 %
Porcentaje de área con datos suficientes (> 10 por 100 km²): 95.23 %
Calculo total¶
Porcentaje de ecorregiones con datos suficientes (> 10 por 100 km²): 93.06 %
Porcentaje de área con datos suficientes (> 10 por 100 km²): 66.84 %
Generar archivo con reporte
indicator_columns = [
"Indicator code", "Indicator",
"Does this data row represent a disaggregation",
"Disaggregation type", "Disaggregation",
"Year", "Unit", "Value", "Footnote"
]
indicator_code = "21.1"
indicator_name = "21.1 Indicator on biodiversity information for monitoring the Kunming-Montreal Global Biodiversity Framework"
year_indicator = 2026indicator_data = [
# Global ones
[
indicator_code, indicator_name, "No",
None, None, None,
"Percentage of ecosystems", 100 - (suficientes * 100 / total),
"Percentage of ecosystems with deficient data (< 10 per 100 km²)"
],
[
indicator_code, indicator_name, "No",
None, None, None,
"Percentage of ecosystems", 100 - (km_suficientes * 100 / km_totales),
"Percentage of area with deficient data (< 10 per 100 km²)"
],
# Marine
[
indicator_code, indicator_name, "Yes",
"Subindicator", "Gap Analysis", 2026,
"Percentage of ecosystems", 100 - (suficientes_marino * 100 / total_marino),
"Percentage of marine ecoregions with deficient data (< 10 per 100 km²)"
],
[
indicator_code, indicator_name, "Yes",
"Subindicator", "Gap Analysis", 2026,
"Percentage of area", 100 - (km_suficientes_marino * 100 / km_totales_marino),
"Percentage of marine area with deficient data (< 10 per 100 km²)"
],
# Terrestrial
[
indicator_code, indicator_name, "Yes",
"Subindicator", "Gap Analysis", 2026,
"Percentage of ecosystems", 100 - (suficientes_terrestre * 100 / total_terrestre),
"Percentage of terrestrial ecoregions with deficient data (< 10 per 100 km²)"
],
[
indicator_code, indicator_name, "Yes",
"Subindicator", "Gap Analysis", 2026,
"Percentage of area", 100 - (km_suficientes_terrestre * 100 / km_totales_terrestre),
"Percentage of terrestrial area with deficient data (< 10 per 100 km²)"
],
]
indicator = pd.DataFrame(indicator_data, columns=indicator_columns)
indicator.to_csv("indicador_21_1.csv", header=True, index=False)
indicator- GBIF.org User. (2026). Occurrence Download. The Global Biodiversity Information Facility. 10.15468/DL.3Z8UUM